


Ottimizzare il web per l'AI: la proposta LLMS.txt
Che però forse è inutile...
Ciao!
Ultimamente nelle nicchie più nerd di internet si parla di llms.txt, un nuovo ipotetico standard per i siti web con l’obiettivo di rendere i loro contenuti più appetibili per l’AI.
È un’idea curiosa, che indipendentemente dal fatto che sia utile o meno (spoiler: ci sono opinioni molto contrastanti), è interessante approfondire.

E allora scopriamo perchè nasce questo file di testo (simile alla sitemap o a robot.txt), che cosa contiene, com’è strutturato e le sue varianti
Vai!
Da dove arriva llms.txt?
Quando facciamo una domanda ad un chatbot (ChatGPT, Gemini, Copilot…) molto spesso per la generazione della risposta viene fatta una ricerca online per ricavare informazioni in vari siti web, forum e blog potenzialmente più aggiornati.
Questa tecnica si chiama RAG (Retrieval Augmented Generation) e permette agli LLM di andare oltre la propria conoscenza utilizzando informazioni presenti online. Viene fatto scraping di siti web, ricavate le informazioni utili che poi vengono fornite al classico LLM per generare l’output.
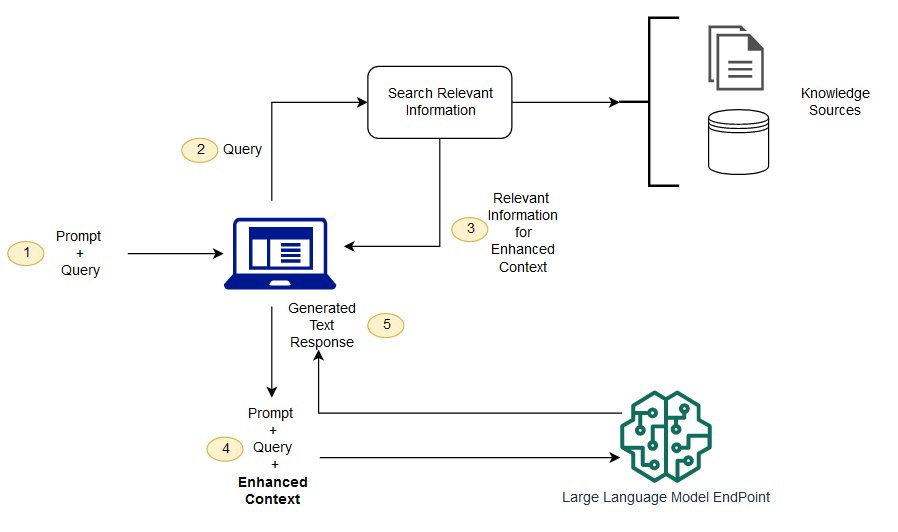
Tuttavia la maggioranza dei siti web è pensata (ancora) per un’utilizzo umano e un traffico derivante dai motori di ricerca: sono quindi presenti tecniche SEO, codice Javascript e CSS, elementi di navigazione e molti altre informazioni extra oltre al contenuto vero e proprio della pagina.
E considerando che tutti gli LLMs hanno una finestra di contesto limitata, ovvero possono gestire una quantità di informazioni non troppo ampia, questo è un problema. La finestra potrebbe venire “saturata” da elementi inutili a discapito di ciò che serve per fornire la risposta.
Da qui nasce la proposta di un file chiamato LLMS.txt, avanzata da Jeremy Howard (co-founder di Answer.ai), che ha l’obiettivo di orientare il RAG nella lettura di un sito web.
Non va totalmente a risolvere il problema di cui abbiamo parlato dato che questo file, scritto con sintassi Markdown, è una sorta di indice per guidare l’AI verso i siti web con il contenuto desiderato senza passare da pagine inutili, come le homepage o sezioni tematiche, che farebbero sprecare tempo e token.
Struttura del File
Lo standard vorrebbe l’utilizzo di una struttura uguale per tutti i file:
Titolo della pagina (H1)
Breve descrizione del sito web, di cosa contiene
Sezione con link esterni che approfondiscano il funzionamento del sito, le caratteristiche del servizio
Sezione (ma anche più di una) con i veri e propri link alle specifiche pagine del sito sottoforma di collegamenti ipertestuali (nome della pagina con sotto l’URL ed eventualmente una spiegazione)
# Bun Documentation
> Bun is a fast all-in-one JavaScript runtime & toolkit designed for speed, complete with a bundler, test runner, and Node.js-compatible package manager.
This documentation covers all aspects of using Bun, from installation to advanced usage.
## Recent Bun Versions
- [Bun v1.2.10](https://bun.sh/blog/bun-v1.2.10.md): setImmediate gets faster. Reliability improvements for filesystem operations. Fixes test.failing with done callbacks. Fixes default idle timeout in Redis client. Fixes importing from 'bun' module with bytecode compilation. Default Docker image updated to Debian Bookworm.
- [Bun v1.2.9](https://bun.sh/blog/bun-v1.2.9.md): Bun.redis is a builtin Redis client for Bun. `ListObjectsV2` support in `Bun.S3Client`, more `libuv` symbols, `require.extensions` & require.resolve paths, bugfixes in `node:http`, `AsyncLocalStorage`, and `node:crypto`. Shell reliability improvements.
## Documentation Sections
### Intro
- [What is Bun?](https://bun.sh/docs/index.md): Bun is an all-in-one runtime for JavaScript and TypeScript apps. Build, run, and test apps with one fast tool.
- [Installation](https://bun.sh/docs/installation.md): Install Bun with npm, Homebrew, Docker, or the official install script.
- [Quickstart](https://bun.sh/docs/quickstart.md): Get started with Bun by building and running a simple HTTP server in 6 lines of TypeScript.
- [TypeScript](https://bun.sh/docs/typescript.md): Install and configure type declarations for Bun's APIsbun.sh/llms.txt / docs.mangopay.com/llms.txt / docs.perplexity.ai/llms.txt
Affinché questo sia efficace è necessario utilizzare un linguaggio semplice e diretto. La struttura Markdown inoltre aiuta il RAG a comprendere la formattazione del testo, e dunque anche la gerarchia dei vari elementi, grazie agli appositi tag. Con le classi CSS dei siti web questo è nettamente più difficile.
Si tratta di un concetto simile a sitemap.xml, altro standard che moltissimi siti web integrano, tuttavia ci sono varie differenze: LLMS.txt contiene anche brevi spiegazioni sui contenuti, formattazione e soprattutto i link diretti alle pagine, che con sitemap andrebbero “ricostruiti”.
La variante con tutto il contenuto della pagina
Una variante di questo standard è LLMS-full.txt, che risponde pienamente al problema sopracitato. Questo file infatti contiene tutto il contenuto di un sito web, tipicamente una documentazione, in formato markdown.
Qualche esempio ⬇️
docs.windsurf.com/llms-full.txt / docs.anthropic.com/llms-full.txt
In questo modo il RAG ha accesso ai contenuti grezzi, senza elementi di distrazione ma comunque con informazioni sulla formattazione, fondamentale per distinguere le informazioni.
Come si crea rapidamente? Chi lo usa?
L’AI per creare gli aiuti per l’AI
In qualche mese sono spuntati rapidamente vari tool basati su AI che permettono di creare questi due file per il proprio sito web. Uno di questi è sviluppato da FireCrawl, altrimenti qui ce n’è uno open-source.
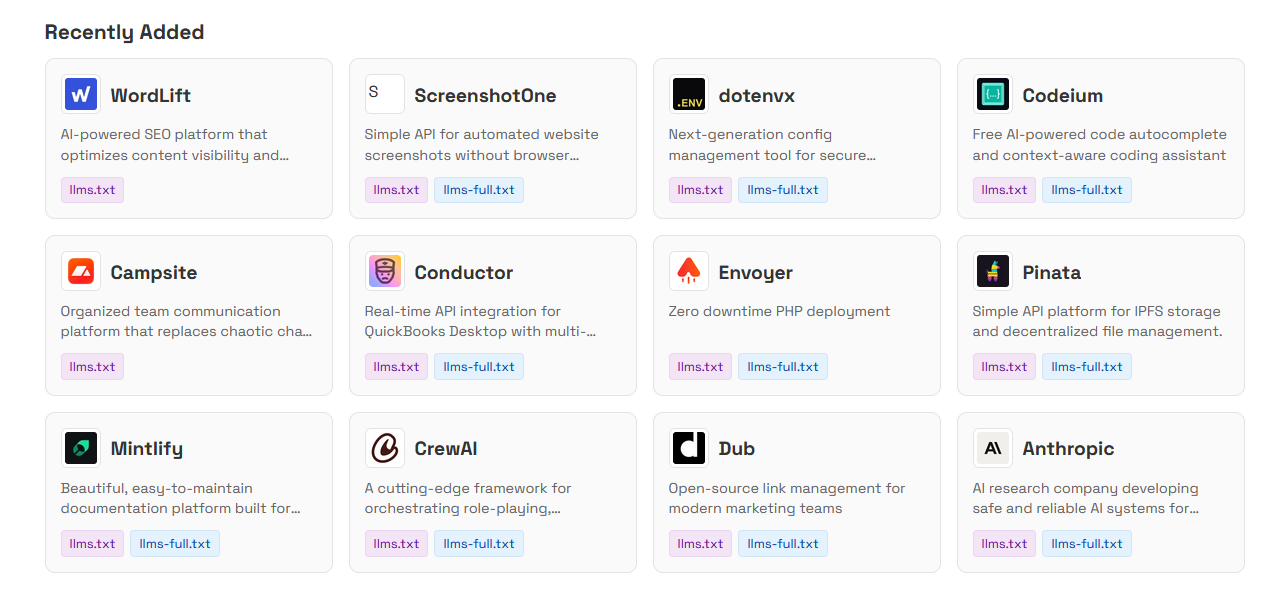
Su questo e questo sito invece si trova un elenco di tutti i domini che includono questi due file. Non sono assolutamente pochi, ce ne sono un bel po’, anche se tutti di piccole startup digital/AI.
Genialata o Vaccata?
LLMS.txt è veramente utile?
Arriviamo quindi alla domanda fondamentale: tutto ciò di cui abbiamo parlato serve davvero per ottimizzare lo scraping e quindi le risposte che otteniamo oppure è inutile (oltre che una perdita di tempo)?
Boh.
Ho deciso di parlarne perché mi sembra un’idea curiosa, indipendentemente dal fatto che sia efficace o meno.
Si tratta ancora di una proposta per uno standard, che chi sostiene può iniziare ad implementare, dunque non è detto che venga effettivamente utilizzata.
I principali LLMs “commerciali” non la supportano ufficialmente, quindi è sostanzialmente inutile per ora.
Su Reddit un utente che ha sott’occhio 20.000 domini ha detto che i file llms.txt non sono mai stati toccati, ad eccezione di piccoli AI agent di nicchia.
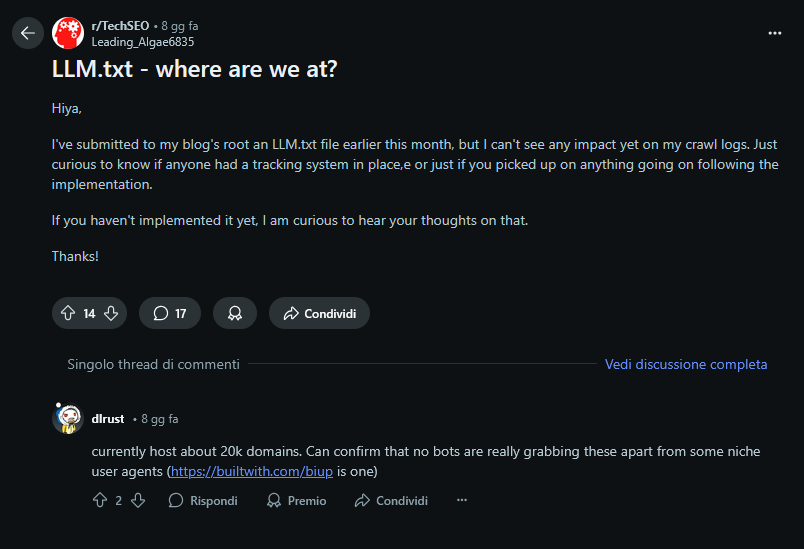
Non è neanche chiaro, proprio perché non c’è ancora un utilizzo su larga scala, se siano effettivamente utili e ottimizzino la ricerca di informazioni da parte dei RAG o se si tratta solamente di paranoie.
Inoltre, per quanto riguarda il file LLMS-full.txt (o eventuali file .md di singole pagine web, altra variante proposta) che contiene tutto il contenuto della pagina senza link esterni, il chatbot potrebbe inserire come fonte proprio questo link che non è pensato per un’utilizzo “umano”.
Insomma, ci sono diversi interrogativi sull’utilità di questo standard, per ora adottato e ritenuto entusiasmante solamente dai veri AI-addicted.
Su Substack esistono i commenti, pronti ad accogliere le vostre riflessioni in merito!
🗂️ Cose Interessanti
Anche le Intelligenze Artificiali procrastinano, una disamina dell’evoluzione dei chatbot e dei loro “bug” per cui si rifiutano di lavorare
AV1 tra promessa e realtà. La rivoluzione dello streaming ostacolata dall'hardware
Grazie per essere arrivati fino a qui, spero che abbiate apprezzato questo post.
A presto 👋🏻